Webmaster-Zentrale Blog
Offizielle Informationen zum Crawling und zur Indexierung von Webseiten und News für Webmaster
Wie bestimmt Google die kanonische Quelle von Content im Web?
Montag, 31. Oktober 2011
In Matt Cutts' heutiger Video-Antwort dreht es sich um das Thema Duplicate Content, welches viele von euch immer wieder beschäftigt. Matt Cutts erklärt, welche Signale Google benutzt, um zwischen identischen Inhalten auf verschiedenen Websites zu unterscheiden und den Urheber festzustellen.
Die heutige Frage kommt aus Chicago, Illinois. Willy F. möchte wissen: "Wie bestimmt Google die kanonische (canonical) Quelle von Inhalten?"
Das ist eine gute Frage. Wir hatten immer unterschiedliche Antworten darauf, da wir ständig an neuen Algorithmen und Methoden arbeiten, um genau zu bestimmen, woher Inhalte ursprünglich stammen. Ich möchte euch die Signale vorstellen, die wir dazu verwenden. Ein Signal ist beispielsweise, wann und wo wir Content zum ersten Mal gesehen haben. Wenn Inhalte verfasst und veröffentlicht und von uns gecrawlt werden und zwei Jahre später an einer anderen Stelle wieder auftauchen, ist sehr wahrscheinlich unser erster Fundort die Quelle.
Es gibt viele Blogs und Content-Management-Systeme, die ping-fähig sind, wie WordPress oder Blogger. Sobald ihr einen Beitrag postet, aktualisiert oder veröffentlicht, könnt ihr einen Ping an Blog- und Echtzeit-Suchmaschinen oder an Google senden. Damit können wir den Zeitpunkt, zu dem der Beitrag gepostet wurde, eindeutiger bestimmen und ihn somit unter identischen Inhalten identifizieren.
Dann gibt es natürlich noch PageRank. Bei identischem Content wird man der etablierten Website mit dem guten Ruf die Urheberschaft zuschreiben, und nicht etwa einer kurzlebigen Website, die man noch nie gesehen hat, weil sie ganz neu ist, und die einen etwas dubiosen und minderwertigen Eindruck macht.
rel="canonical" ist natürlich ein sehr eindeutiges Signal, den bevorzugten Standort für Inhalte zu kennzeichnen. Eine weniger explizite Methode stellt rel="author" dar. Mit diesem Attribut könnt ihr im Web kennzeichnen, dass Inhalte von euch stammen, oder auf euer Autorenprofil verweisen. Ihr könnt also mit einem Hinweis zeigen, woher Inhalte stammen und ob sie aus bekannten Quellen kommen.
Theoretisch kann man auch Signale auf Website-Ebene verwenden. Wenn wir denken, dass eine bestimmte Website allgemein viel kopiert, und der selbe auf dieser und auf einer anderen Website auftaucht, denken wir eher nicht, dass die Website mit dem vielen Kopierten die Quelle ist, sondern die Website, die schon über längere Zeit einzigartige Inhalte hervorgebracht hat.
Es sind also viele Faktoren denkbar. Es ist so knifflig, da der Googlebot das Web gewissermaßen nur in Stichproben crawlt. Das Web ist unendlich und kann sich innerhalb weniger Millisekunden verändern. Deshalb ist es schwer, beim Crawlen herauszufinden, wann und wo genau Inhalte zum ersten Mal aufgetaucht sind. Wir versuchen dabei, unser Bestes zu geben. Das gelingt uns nicht immer, und dann freuen wir uns über euer Feedback. Es gibt jedenfalls viele verschiedene Hinweise, Signale und Möglichkeiten, um die kanonische bzw.ursprüngliche Quelle von Inhalten zu bestimmen.
Veröffentlicht von Daniela Loesser, Search Quality Team
Brauche ich eine robots.txt, wenn ich Crawler gar nicht blocken will?
Freitag, 28. Oktober 2011
Heute beantwortet Matt Cutts eine Webmaster-Frage zum Thema robots.txt. Eine robots.txt-Datei ist nützlich, um das Crawling und Indexieren des Contents durch Suchmaschinen zu steuern und einzuschränken. Ist eine robots.txt-Datei jedoch auch nötig, wenn man überhaupt keine Crawling-Einschränkungen haben möchte?
Die heutige Frage kommt aus Pennsylvania. Corey S. fragt: "Was ist besser? Eine leere robots.txt-Datei, eine robots.txt-Datei mit "User Agent: * Disallow" ohne Einschränkungen oder gar keine robots.txt-Datei?"
Sehr gute Frage, Corey. Ich denke, die beiden ersten Varianten sind die besten. Keine "robots.txt"-Datei zu haben, ist ein bisschen riskant. Nicht allzu riskant, aber schon ein bisschen. Ohne Datei gibt manchmal der Webhost die 404-Fehlermeldung aus, und das kann zu sehr seltsamem Verhalten führen. Und zum Glück entdecken wir so etwas ohne Probleme, also liegt auch hier das Risiko bei nur 1 %.
Wenn möglich würde ich aber eine robots.txt-Datei verwenden. Ob sie leer ist oder ob ihr festlegt "User-Agent: * Disallow" ohne Einschränkung, was heißt, dass jeder alles crawlen kann, ist ziemlich egal. In syntaktischer Hinsicht behandeln wir beide genau gleich.
Ich persönlich fühle mich mit "User-Agent: * Disallow:" wohler, weil eindeutig festgelegt ist, dass alles gecrawlt werden darf. Wenn sie leer ist, dann... Es war offensichtlich kein Problem, die robots.txt-Datei zu erstellen, deshalb wäre es toll, diesen Hinweis zu haben, der sagt: "Genau so, wie es hier steht, soll das Verhalten aussehen". Es könnte ja auch sein, dass jemand aus Versehen den gesamten Inhalt der Datei gelöscht hat.
Wenn ich die Wahl hätte, würde ich mich für eine robots.txt-Datei mit "User-Agent: *" entscheiden, in der alle Einschränkungen genau festgelegt sind. Ich denke aber, eine leere Datei ist vollkommen OK. Komplett ohne Datei besteht das wirklich geringe Risiko, dass euer Webhost seltsam oder ungewöhnlich reagiert, z. B. mit der Meldung "Sie haben keine Berechtigung, diese Datei zu lesen". Dann wird's komisch.
Das ist also nur ein ganz kleiner Tipp, wie ihr eine robot.txt-Datei erstellt. Vorausgesetzt, ihr habt nichts dagegen, dass der Googlebot eure Inhalte crawlt.
Veröffentlicht von Daniela Loesser, Search Quality Team
Benutzerdefinierte Suche in den Webmaster-Tools
Mittwoch, 26. Oktober 2011
Benutzerdefinierte Suchen
(Custom Search Engines CSEs) ermöglichen es euch, die vollwertige Google-Suchfunktion in eure Website einzubauen und auf eure Bedürfnisse zuzuschneiden. Ihr könnt auf einer Seite oder über mehrere hinweg suchen, das Aussehen an eure Seite anpassen und sogar Geld mit
Adsense für Suchergebnisseiten
verdienen. Von nun an wird es noch einfacher, die benutzerdefinierte Suche direkt aus den
Webmaster-Tools
zu verwenden.
Wenn ihr dieses Feature noch nie verwendet habt, klickt einfach auf "Benutzerdefinierte Suche" im Labs-Bereich und wir erstellen automatisch eine benutzerdefinierte Suche mit den Standardeinstellungen, die ausschließlich eure Website durchsucht. Ihr könnt die Suche an dieser Stelle konfigurieren oder direkt das Code-Snippet nehmen um die Google-Suche in eure Seite einzubauen. Ihr könnt immer in das Bedienfeld für die benutzerdefinierte Suche gehen, um weiterführende Anpassungen vorzunehmen.
Wenn ihr einmal eure benutzerdefinierte Suche eingerichtet habt (oder wenn sie bereits in eure Seite integriert ist), könnt ihr jeder Zeit auf den Link "Benutzerdefinierte Suche" in Labs klicken, um eure benutzerdefinierte Suche zu verwalten ohne die Webmaster-Tools zu verlassen.
Wir hoffen, dass dieses neue Feature euch dabei hilft, es euren Nutzern zu erleichtern eure Website zu durchsuchen. Wenn ihr Fragen habt, postet sie einfach in unserem
Webmaster-Hilfeforum
.
Gepostet von
Sharon Xiao
, Software Engineering Intern, und Ying Huang, Software Engineer (Übersetzung von
Dominik Zins
, Search Quality)
Wie schaut bei Google der Kundenservice aus?
Montag, 24. Oktober 2011
Heute spricht Matt Cutts in seinem Video über den Kundenservice bei Google, welchem Problem wir gegenüberstehen und wie wir versuchen es mit unseren unterschiedlichen Service-Angeboten zu lösen, um euch bestmöglich zu unterstützen.
Die heutige Frage kommt aus Kanada von Cale McNulty: "Kannst du etwas zu Googles Verständnis von Kundenservice sagen und erklären, warum ihr Algorithmen anstatt Menschen einsetzt?"
Kundenservice bzw. Nutzer-Support ist eine knifflige Angelegenheit. Als Unternehmen bietet man diese Dienste normalerweise nur den Personen an, die auch die Produkte kaufen. Selbst bei extrem erfolgreichen Unternehmen ist die Zahl der Personen, die einen Kundenservice benötigen, doch relativ gering. Dagegen unterstützt Google alle Personen im Web, die unsere kostenlosen Dienste nutzen möchten. Im Web gibt es schätzungsweise zwei Milliarden Nutzer. Viele davon nutzen Google.
Dewitt Clinton hat eine Analyse durchgeführt. Er ging von einer Milliarde Nutzern aus, von denen jeder alle drei Jahre ein Problem meldet, das in zehn Minuten gelöst werden kann. Er hat das durchgerechnet und herausgefunden, dass wir unter diesen Umständen über 20.000 Mitarbeiter im Kundenservice bzw. im Nutzer-Support beschäftigen müssten. Also bei etwa einer Milliarde Nutzern, bei denen alle drei Jahre ein Problem auftaucht, das in zehn Minuten gelöst werden kann. Bei zwei Milliarden Nutzern bräuchten wir also 40.000 Service-Mitarbeiter, richtig?
Wie man es auch dreht und wendet, es ist einfach schwierig, die Fragen so vieler Menschen zu beantworten, die beispielsweise wissen möchten, wie Google funktioniert. Oder bei über 200 Millionen Domains ausreichend Support für Webmaster anzubieten. Wir möchten vor allem viele Menschen auf einmal erreichen. Fragen individuell auf Twitter zu beantworten ist gut, hilft aber nur einer Person weiter. Das Gleiche gilt für E-Mail. Mit einer E-Mail an eine Person löst man nicht die Probleme der ganzen anderen Nutzer. Wir haben überlegt, wie wir den Support am besten handhaben, und arbeiten ständig daran.
GoogleGuy ging beispielsweise 2001 im Webmaster-Forum online. Das war eine gute Lösung, weil von den Antworten dort viele Menschen profitieren konnten. AdWords Advisor startete kurze Zeit später, und seitdem wurden dort tausende Fragen beantwortet. Einige Jahre später entwickelten wir die Foren, damit sich Nutzer austauschen und gegenseitig helfen können. Das funktioniert gut. Wir arbeiten also an vielen verschiedenen Lösungen und probieren immer unterschiedliche Sachen aus. Dazu gehören beispielsweise Blogs oder Webmaster-Chats. Diese Webmaster-Videos werden oft von mehreren Tausend Nutzern angeschaut, erreichen also viele Menschen.
Wir haben auch den AdWords-Support eingerichtet. Wenn ihr AdWords verwendet, könnt ihr eine Telefonnummer anrufen und dort eure Fragen stellen. Wenn euch also jemand mitteilt, dass ihr bestimmte Keywords besser nicht verwendet oder nicht verwenden dürft, könnt ihr mit einer Person direkt darüber diskutieren. Jeder bei AdWords kann anrufen und sich über Telefon helfen lassen.
Wir arbeiten ständig an weiteren Lösungen. Das ist wirklich schwierig. Bei so vielen Internetnutzern ist es wahrscheinlich schwer vorstellbar, wie groß die Zahl der Leute tatsächlich ist, die Fragen stellen oder mehr über Google oder ihre Website erfahren möchten. Es ist wirklich schwierig, allen einen angemessenen Support zu bieten. Bei Google beschäftigen wir uns ständig mit dieser Frage und möglichen Lösungen. Wir nehmen eure Ideen und Vorschläge deshalb gerne entgegen.
Ich konnte euch hoffentlich zeigen, dass wir euch Support bieten möchten, aber dass das gar nicht so einfach ist. Wir versuchen, gute Lösungen dafür zu finden. Und Algorithmen sind eine gute Lösung. Google Webmaster-Tools sind eine Hilfe zur Selbsthilfe. So entdeckt ihr eure Fehler selbst, ihr findet eure Links und erkennt, warum eure Website langsam ist. Das ist überaus effektiv, denn ihr könnt beispielsweise eine URL selbst entfernen und wir erreichen auf diese Art viel mehr Menschen.
Ihr seht also, dass wir viele verschiedene Lösungen anbieten. Wir versuchen, Fragen beispielsweise zu rel="canonical" oder zu bevorzugten Domains mit oder ohne www in der Selbsthilfe zu beantworten, damit ihr euer Problem ohne uns lösen könnt. Das funktioniert oft richtig gut. Manchmal könnten wir es noch besser machen. Aber wir arbeiten ständig daran, uns zu verbessern. Also vielen Dank für die Frage.
Veröffentlicht von Daniela Loesser, Search Quality Team
Wie bestimmt Google die Geschwindigkeit einer Website?
Freitag, 21. Oktober 2011
Die Geschwindigkeit, mit der eine Seite für die Nutzer läd, kann Einfluss auf das Ranking und vor allem die Nutzerzufriedenheit haben. Heute erklärt Matt Cutts, wie Google die Website-Leistung in den Webmaster-Tools ermittelt und wieviel Einfluss dieser Wert auf das Ranking hat.
Die heutige Frage kommt aus Großbritannien. DisgruntledGoat möchte wissen: "Wie bestimmt Google die Geschwindigkeit einer Seite? In den Google Webmaster-Tools werden einige Seiten als sehr langsam aufgeführt, mit mehr als 8 Sekunden. Ich habe allerdings Tests mit älteren Computern und Browsern durchgeführt, die bei Weitem nicht solange zum Laden brauchen. Wieso gibt Google so lange Zeiten an?"
Wir arbeiten mit Daten aus der Google Toolbar, genauer gesagt mit Daten von Leuten, die diese aktiviert haben. So erhalten wir realistische Ladezeiten. Wir überprüfen beispielsweise, wie lange eine bestimmte Seite zum Laden braucht, wenn man sie aus den USA abruft. Wenn die Ladezeit lang ist, liegt das nicht unbedingt an eurer Website. Auch die Netzwerkverbindung könnte die Ursache sein. Und das sollte man im Hinterkopf behalten. Darauf nehmen die verschiedenen Nutzer Einfluss, von denen manche vielleicht eine Dial-Up-Verbindung oder eine langsame Verbindung haben. Wenn 500-KB-Seiten ins Internet gestellt werden, wird oft nicht an die Leute gedacht, die eine langsamere Verbindung haben.
Unsere Daten stammen also vor allem aus der Google Toolbar. Wir überprüfen, welche Situation sich realen Nutzern stellt. Wenn dabei viele Nutzer von langen Ladezeiten betroffen sind, kann sich das auf die Gesamtbewertung auswirken. Allerdings hat die Geschwindigkeit einer Website nur bei einer von hundert Suchanfragen tatsächlich einen erkennbaren Einfluss auf das Ranking. Somit stellt die Geschwindigkeit gerade einmal für eine von tausend Websites ein Problem dar.
Natürlich ist es gut, wenn ihr eure Website beschleunigen und Nutzern die Ergebnisse schneller anzeigen könnt. Das verbessert die Nutzererfahrung auf eurer Website. Studien belegen, dasss ich das auf jeden Fall auszahlt. Trotzdem würde ich mir nicht zu sehr den Kopf darüber zerbrechen. Ich hoffe, es ist jetzt etwas klarer, welche Berechnungen wir anstellen, wenn wir denken, dass eine Website in den Google Webmaster-Tools langsam ist.
Veröffentlicht von Daniela Loesser, Search Quality Team
Sprachbarrieren mit übersetzten englischsprachigen Suchergebnissen beseitigen
Mittwoch, 19. Oktober 2011
Wir haben eine neue Funktion in der Google-Suche eingeführt, die es ermöglicht, in Sprachen, in denen wenige Seiten vorliegen, Ergebnisse aus dem englischen Sprachraum zu ergänzen. Obwohl die neue Funktion nicht in deutscher Sprache verfügbar ist, weil das Informationsangebot hier sehr üppig ist, wollten wir euch diese spannende Neuerung nicht vorenthalten. Vielleicht befindet sich ja auch der ein oder andere Muttersprachler einer der 14 Sprachen unter euch, die mit diesem neuen Feature auf ein erheblich größeres Maß an Informationen zugreifen können, als zuvor.
Für englische Muttersprachler ist es selbstverständlich, dass sie unabhängig vom Gegenstand ihrer Suche immer Antworten online finden können. Aber was tun Nutzer, deren Muttersprache Hindi, Walisisch oder Afrikaans ist? Der Anteil der Online-Inhalte, die je Muttersprachler in Hindi zur Verfügung stehen, beträgt lediglich 1 Prozent der zahllosen Inhalte im Web, die je Muttersprachler in Englisch verfügbar sind. Wenn Nutzer also eine Sprache sprechen, in der online weniger Inhalte zu finden sind, liegen die relevantesten Ergebnisse für ihre Suche möglicherweise in englischer Sprache vor.
Ab sofort sehen sie eventuell neben den Suchergebnissen in ihrer Standardsprache auch relevante englische Suchergebnisse. Sie sollen ihnen dabei helfen, die Sprachbarriere zwischen sich und den benötigten Antworten zu überwinden. Angenommen, ein Nutzer spricht Hindi und sucht nach Informationen zum Bergsteigen, dann möchten wir sicherstellen, dass er auch die relevanten Seiten in englischer Sprache findet. Ihm wird sogar eine Übersetzung dieser Seiten in seine Muttersprache angezeigt.
Sprache ist eines der größten Hindernisse, die sich uns beim Versuch, Informationen universell verfügbar zu machen, in den Weg stellt. Wir nutzen daher in
zunehmendem Umfang die maschinelle Übersetzung
, um Suchergebnisse sprachübergreifend zur Verfügung zu stellen. Dies ist insbesondere bei Sprachen wichtig, in denen online nur in geringem Maße Inhalte verfügbar sind. Nutzer sollen außerdem die relevantesten Informationen finden, und zwar unabhängig von der Sprache, in der sie suchen. Wir setzen die maschinelle Übersetzung ein, um die Suche zu übersetzen und die Seiten bereitzustellen, welche die Frage am besten beantworten. Die passenden Suchergebnisse werden dabei übersetzt.
Es werden relevante englischsprachige Seiten angezeigt, wenn ihr in einer der folgenden vierzehn Sprachen sucht: Afrikaans, Albanisch, Hindi, Isländisch, Katalanisch, Malaiisch, Maltesisch, Mazedonisch, Norwegisch, Serbisch, Slowakisch, Slowenisch, Suaheli und Walisisch. Wenn man auf den Haupttitel des Ergebnisses klickt, gelangt man zur englischsprachigen Seite. Der übersetzte Link darunter führt hingegen zu einer übersetzten Seite. Wir hoffen, dass unsere Nutzer auf diese Weise die Informationen finden, die sie benötigen, und zwar unabhängig von der Sprache, in der diese verfasst sind.
Gepostet von Jordan Gilliland, Software Engineer - Cross Language Search Team (Veröffentlicht von
Dominik Zins
)
Gesamtansicht von Websites in den Suchergebnissen
Montag, 17. Oktober 2011
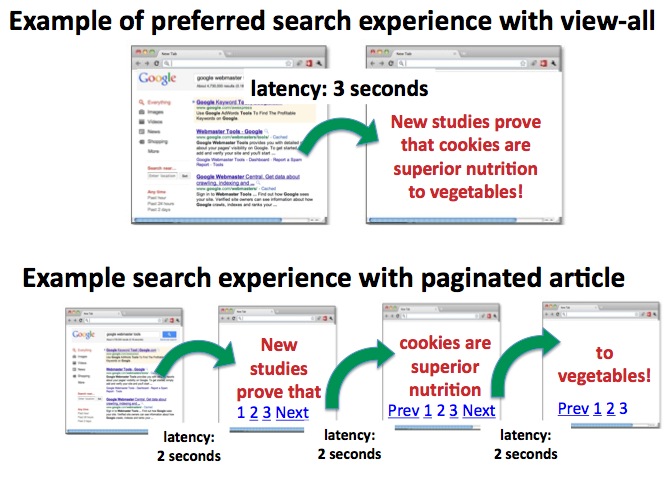
Tests haben uns gezeigt, dass Nutzer bei der Suche die gesamten Informationen auf einer Einzelseite gegenüber einer Komponentenseite bevorzugen, die nur einen Teil der Informationen sowie willkürliche Seitenumbrüche enthält. Seitenumbrüche zwingen die Nutzer, auf "Weiter" zu klicken und eine zusätzliche URL zu laden.
Nutzer bevorzugen häufig die "Gesamtansicht"-Seite gegenüber Komponentenseiten mit willkürlichen Seitenumbrüchen und schlechterer Latenz.
Für eine bessere Nutzererfahrung versuchen wir deshalb, in den Suchergebnissen die Einzelseite auszugeben, wenn wir sehen, dass in einer Content-Serie (z. B. seite-1.html, seite-2.html) ebenfalls eine Einzelseite (z. B. seite-alles.html) verfügbar ist. Wenn eure Website eine "Gesamtansicht"-Option bietet, braucht ihr nichts weiter zu tun. Wir kümmern uns um alles. Außerdem werden Indexierungseigenschaften wie Links von den Komponentenseiten der Content-Serie in der "Gesamtansicht"-Seite zusammengeführt.
Allerdings wirkt sich eine hohe Latenz der "Gesamtansicht"-Option möglicherweise negativ auf ihre Beliebtheit aus.
Interessanterweise sank bei einer hohen Latenz die Beliebtheit der "Gesamtansicht"-Seite bei den Nutzern, beispielsweise wenn sie viele Bilder enthielt und deshalb eine lange Ladezeit hatte. Das ist verständlich, da Nutzer mit Ergebnisseiten, die sich nur langsam aufbauen,
bekanntermaßen unzufrieden sind
. Da eine "Gesamtansicht"-Seite allgemein gewünscht wird, müssen Webmaster diesen Faktor mit der Ladezeit der Seite und der Nutzererfahrung abstimmen.
Best Practices für eine Content-Serie
1.
Eure Website enthält "Gesamtansicht"-Seiten
Wir suchen die "Gesamtansicht"-Version für euren Content und, falls verfügbar, die dazugehörigen Komponentenseiten. Ihr braucht nichts weiter zu tun! Wenn ihr uns ein wenig unterstützen möchtet, könnt ihr rel="canonical" von euren Komponentenseiten zur "Gesamtansicht"-Seite verweisen lassen. Wir können dadurch eure Content-Serie leichter finden.
rel="canonical" kann von der gleichen Information in einer URL-Serie aus die Obermenge des Contents, also die "Gesamtansicht"-Seite, angeben.
Warum funktioniert das?
Im Schaubild könnte seite-2.html einer Serie als Standardziel seite-alles.html festlegen, weil seite-alles.html eine Obermenge des Inhalts von seite-2.html ist. Wenn eine Suchanfrage gestellt und seite-alles.html in den Suchergebnissen ausgewählt wird, werden die relevanten Informationen von seite-2.html in seite-alles.html angezeigt, auch wenn die Suchanfrage am stärksten mit seite-2.html verbunden ist.
seite-2.html sollte allerdings nicht seite-1.html als Standard festlegen, weil der Content von seite-2.html nicht in seite-1.html enthalten ist. Möglicherweise enthält seite-2.html für die Suchanfrage relevanten Content. Wenn in seite-2.html allerdings seite-1.html als Standard festgelegt ist, wird seite-1.html in den Suchergebnissen angezeigt. In diesem Fall müssen Nutzer zu einer weiteren Seite navigieren, um zur gewünschten Information zu gelangen. Ein ungenügendes Suchergebnis stellt eine schlechte Nutzererfahrung dar. Es könnte außerdem dazu führen, dass nicht die gewünschten Besucher auf eure Website kommen.
Wenn ihr allerdings nicht möchtet, dass eure "Gesamtansicht"-Seite in den Suchergebnissen auftaucht, tut Folgendes: 1) Stellt sicher, dass die Komponentenseiten in der Serie kein rel="canonical" zur "Gesamtansicht"-Seite enthalten. 2) Markiert mit einem Standardverfahren die "Gesamtansicht"-Seite als "
noindex
".
2.
Wenn ihr einzelne Komponentenseiten anzeigen möchtet oder keine "Gesamtansicht"-Seite verfügbar ist
Möglicherweise trifft einer der beiden Fälle auf eure Website zu:
Die "Gesamtansicht"-Seite eignet sich nicht als Suchergebnis, beispielsweise aufgrund zu langer Ladezeiten oder einer zu komplexen Navigation.
Eure Besucher bevorzugen eine Anzeige mit mehreren Seiten und in den Suchergebnissen die Weiterleitung auf eine Komponentenseite und nicht auf die "Gesamtansicht"-Seite.
In diesen Fällen könnt ihr die
HTML-Standardelemente rel="next" und rel="prev"
verwenden, um die Beziehung zwischen den Komponentenseiten in eurer Content-Serie festzulegen. Wenn ihr das richtig umgesetzt habt, versucht Google
die Indexierungseigenschaften wie Links zwischen den Komponentenseiten/URLs zusammenzuführen und
eure Besucher von den Komponentenseiten zur relevantesten Seite/URL weiterzuleiten. Üblicherweise ist die relevanteste Seite die erste Seite eures Inhalts. Möglicherweise leiten unsere Algorithmen eure Besucher jedoch zu einer der Komponentenseiten in der Serie weiter.
Es kommt öfter vor, dass Webmaster rel="canonical" von Komponentenseiten zur ersten Seite der Serie falsch verwenden, beispielsweise mit rel="canonical" von seite-2.html zu seite-1.html verweisen. Wir raten euch allerdings von dieser Implementierung ab, weil Komponentenseiten keinen doppelten Content enthalten. Es ist besser, rel="next" und rel="prev" zu verwenden.
Zusammenfassung
Da Nutzer allgemein die "Gesamtansicht"-Option bei Suchergebnissen bevorzugen, versuchen wir, diese Version ausfindig zu machen und auszugeben. Wenn ihr eine Content-Serie habt, braucht ihr weiter nichts zu tun. So könnt ihr uns zeigen, wie wir Nutzern eure Informationen ausgeben sollen:
1. Zur Optimierung eurer "Gesamtansicht"-Seite könnt ihr rel="canonical" von den Komponentenseiten zur Einzelseiten-Version weiterleiten lassen.
2. Wenn eine "Gesamtansicht"-Seite die Nutzererfahrung auf eurer Website verschlechtert, könnt ihr die
Attribute rel="next" und rel="prev"
verwenden. Das ist für Google ein eindeutiger Hinweis, diese Content-Serie zu identifizieren und weiterhin eine Komponentenseite in den Ergebnissen anzuzeigen.
Fragen?
Wie immer beantworten wir euch gerne alle Fragen in unserem
Webmaster-Hilfeforum
.
Gepostet von Benjia Li & Joachim Kupke, Software Engineers, Indexing Team (Veröffentlicht von
Dominik Zins
, Search Quality)
Zählen mehrere Links von einer Seite auf eine andere?
Freitag, 14. Oktober 2011
Einige werden sich vielleicht schon damit beschäftigt haben, wie sie am besten ihren PageRank gezielt durch ausgesuchte interne und externe Links beeinflussen können. Im heutigen Video erklärt Matt Cutts, was er von PageRank-Sculpting hält, wie PageRank ursprünglich funktioniert und auf was ihr euch statt PageRank-Sculpting besser konzentriert.
Die heutige Frage beschäftigt sich so ein bisschen mit PageRank-Sculpting. Sie lautet: "Hi Matt. Wenn wir mehr als einen Link von Seite A zu Seite B erstellen, geben wir damit mehr PageRank-Juice und zusätzliche Ankertext-Info weiter? Und kannst du uns sagen, ob Links von A zu A gezählt werden?"
OK, erst beantworte ich eure Frage und dann erkläre ich euch, warum ihr euch in diesem Stadium nicht darüber den Kopf zerbrechen solltet. Schauen wir uns nochmal die ursprüngliche Fassung von PageRank von Larry und Sergei an - lang lang ist's her - zumindest Larry. Der PageRank einer Seite wird anhand aller auf diese Seite verweisenden Links berechnet. Einiges davon verschwindet oder verfällt, aber keine Sorge, dadurch wird alles konvergiert. Ihr nehmt den verbleibenden PageRank und teilt ihn durch die Zahl der ausgehenden Links auf dieser Seite. Wenn ich also vier solcher Links habe, teile ich den auf dieser Seite verbleibenden PageRank durch vier, und der PageRank wird gleichmäßig an alle Links weitergegeben. Das macht Sinn.
Was passiert aber, wenn beispielsweise zwei dieser Links auf Seite B verweisen und zwei auf andere Seiten? Und die Antwort ist, zumindest laut der ursprünglichen Fassung in der PageRank-Publikation, dass beide Links den PageRank weitergeben würden. Ich werde nicht weiter auf Ankertexte eingehen, aber beide Links würden PageRank weitergeben. Und dieser Link würde so doppelt so viel PageRank weitergeben. So lief das im ursprünglichen PageRank.
Die zweite Frage war, ob ein Link von A zu A, also eine Selbstschleife, mitgezählt wird. Und die Antwort lautet: Ja,in der ursprünglichen Fassung von PageRank wird er mitgezählt. Somit hab ich eure Fragen also beantwortet.
Aber ich möchte euch gerne das Gesamtbild zeigen. Und das sieht so aus: Wenn ihr über das bisschen PageRank-Sculpting nachdenkt, nutzt ihr eure Zeit wahrscheinlich nicht besonders effektiv, wenn ihr euch darüber den Kopf zerbrecht, wie ihr so viel PageRank wie möglich herausholen könnt. "Wie kann ich möglichst viel PageRank ansammeln oder durch meine Website laufen lassen?" und solche Sachen. Das bringt wahrscheinlich nicht so viel, wie sich auf das Erstellen toller Inhalte zu konzentrieren, auf die viele Leute verlinken, wodurch ihr mehr PageRank bekommt, der ganz natürlich durch eure Website fließt.
Da gibt es also ein paar ganz einfache Dinge, die ihr tun könnt. Wenn ihr auf eurer Website oben links ein kleines Logo oder etwas Ähnliches habt, das zur Startseite zurückführt, wenn man darauf klickt, ist das eine große Hilfe für die Besucher eurer Website. Das trägt zur guten Navigation bei. Deshalb ist es gut, sowas einzubauen.
Wenn ihr Seiten habt, die besonders wichtig sind, versteckt sie nicht hinter 15 Links. Und damit meine ich nicht Verzeichnislinks. Ich meine damit, dass man sich wirklich durch 15 Links klicke nmuss, um die Seite zu finden. Wenn eine Seite wichtig oder besonders rentabel ist oder zu vielen Conversions führt, macht euch das zunutze. Erstellt einen Link von der Startseite zu dieser Seite. Solche Sachen sind überaus sinnvoll, weil eure Besucher auf eine Seite kommen, ein interessantes Produkt entdecken, eine Conversion stattfindet, das Produkt gekauft wird usw.
Aber euch den Kopf zu zerbrechen, wie ihr eure Website gestalten könnt, um den maximalen PageRank durchlaufen zu lassen, sodass der PageRank erhalten bleibt und alle internen Ankertexte maximiert werden, macht keinen Sinn und ihr könnt annehmen, dass wir nach verschiedenen Methoden suchen, um sicherzustellen, dass all dieser PageRank... Wenn alle PageRank anhäufen, hilft das niemandem weiter. Also setzen wir Mathematik, Algorithmen und andere Methoden ein, die verhindern, dass ihr große Vorteile davon habt, wenn ihr euch zu sehr auf PageRank-Sculpting konzentriert.
Ich bin absolut der Meinung, dass ihr euch weniger um solche Dinge Gedanken machen, sondern euch eher darauf konzentrieren solltet, wie ihr eine ansprechende Website und richtig tolle Inhalte für eure Besucher erstellen könnt. Vorallem auf diese Art erhaltet ihr jede Menge Links auf eure Website. Was ihr dann mit eurem PageRank macht, ist eher nebensächlich.
Veröffentlicht von Daniela Loesser, Search Quality Team
Braucht man heute noch einen DMOZ-Eintrag?
Mittwoch, 12. Oktober 2011
Die heutige Frage an Matt Cutts dreht sich um das Open Directory Project, DMOZ. Matt Cutts erklärt im Video, wie Google DMOZ in der Vergangenheit genutzt hat und wie nützlich ein Eintrag in diesem Verzeichnis heute ist.
Hallo! Ich bin's, Matt Cutts. Wir zeichnen derzeit 48 Stunden Webmaster-Videomaterial auf und können hoffentlich viele Fragen beantworten. Für die komplexeren benötigen wir ein Whiteboard, andere lassen sich schneller klären. Packen wir's also an und beantworten eine Frage. Sie kommt von Flo aus Spanien. Flo möchte wissen: "Welche Rolle spielt ein DMOZ-Eintrag hinsichtlich des Rankings? Einige der Websites in meiner Nische weisen eine Platzierung an erster Stelle auf. Und zwar nur, weil sie im DMOZ eingetragen sind. Die Qualität ihres Contents ist, milde ausgedrückt, dürftig. Heutzutage ist es quasi unmöglich, ins DMOZ aufgenommen zu werden. Warum greift Google also noch darauf zurück?"
Okay. Eine Sache, bevor wir uns näher mit dem DMOZ befassen: In einigen Fällen lässt sich das Ranking einer Website schwer nachvollziehen. In der Vergangenheit hat Google den "link:"-Operator eingesetzt, der die Backlinks oder einige Stichproben der Backlinks zurückgibt. Wir zeigen aber nicht sämtliche Backlinks an, von denen wir wissen. Diese Backlinks zeigen wir eher über die Webmaster-Tools an. Ihr könnt also eure eigenen Backlinks sehen, wir zeigen euch aber keine vollständige Liste der Backlinks eurer Konkurrenten an. Insgesamt ist das eigentlich ganz ausgewogen.
Wenn ihr "link:" verwendet und euch ein Link vom DMOZ angezeigt wird, schließt ihr möglicherweise daraus, dass das der Grund für das Ranking ist. Es kann aber sein, dass es andere Links von Websites mit Content von hoher Qualität gibt, die euch nicht angezeigt werden und beispielsweise von CNN oder der New York Times stammen. Ihr solltet also nicht automatisch Rückschlüsse aus den Backlinks ziehen, die ihr von Google, Yahoo oder gar einem Drittanbietertool seht, und annehmen, dass es sich dabei tatsächlich um alle Links handelt, die Google für vertrauenswürdig oder relevant hält.
Aber befassen wir uns etwas eingehender mit dem DMOZ. DMOZ, auch bekannt als Open Directory Project, hat wirklich gute Dienste als Ressource geleistet. Inzwischen ist DMOZ aber etwas in die Jahre gekommen. Ich habe daher ein paar Informationen für euch dazu, wie Google DMOZ sieht und wie wir mit dem Open Directory Project umgehen. Es gab eine Version des offenen Verzeichnisses von Google, sozusagen das Google Open Directory, das auf Open Directory-Daten zugegriffen und diese verwertet hat, indem das Material nach PageRank sortiert wurde.
Es wurde aber nicht besonders intensiv genutzt. Obwohl es sich um eine der ersten Einführungen neben der direkten Websuche handelte, haben wir kürzlich damit begonnen, es zu deaktivieren. Möglicherweise bleibt es aber für manche Länder weiterhin verfügbar. Beispielsweise in einigen asiatischen Ländern, wo die Eingabe etwas langsamer erfolgt. Da ist das Durchsuchen eines Verzeichnisses möglicherweise schneller. Das Verzeichnis wurde folglich nicht vollständig deaktiviert. Wir haben es aber für viele verschiedene Länder deaktiviert.
Andererseits greift Google manchmal auf das DMOZ zu, um seine Snippets zu nutzen. Wenn ihr z. B. den Zugriff auf eure Seite mit "robots.txt" blockiert, können wir diese Seite nicht crawlen. Wir sehen möglicherweise den Ankertext oder die Anker, die Backlinks, die auf eine Seite verweisen. Aber wir können sie nicht crawlen underfahren, worum es auf der Seite geht. Wir kennen weder den Titel der Seite noch andere derartige Informationen. In solchen Fällen ist es hilfreich, auf DMOZ zurückzugreifen. Denn wenn es sich um eine bekannte Seite handelt, hat möglicherweise ein Redakteur des Open Directory Project vermerkt, worum es auf der Seite geht. Diese Snippets können also hilfreich sein.
Gleichzeitig versuchen wir immer, unsere Annahmen von Zeit zu Zeit zu überprüfen. Und daher führen wir einen Test durch, um herauszufinden, was geschieht, wenn wir nicht mehr auf die Snippets von DMOZ zurückgreifen. Momentan zeichnen sich die Ergebnisse noch nicht ab. Aber so gehen wir vor: Wir führen Tests durch, um zu erfahren, ob es sich noch lohnt– vor dem Hintergrund unserer Annahmen und den Verfahren, die vor einigen Jahren eingesetzt wurden.
OK, abschließend solltet ihr zu DMOZ also wissen, dass ein DMOZ-Eintrag den PageRank nicht nach oben katapultiert oder einen Bonus einbringt. Ein Link von DMOZ hat keinen höheren Stellenwert als Links von anderen Quellen. Es ist lediglich so, dass das Open Directory tendenziell einen höheren PageRank aufweist. Entsprechend wirkt sich ein Link von DMOZ möglicherweise etwas mehr auf den PageRank aus. Aber ein Link von einer sehr guten Seite, etwa wenn ihr einen Zeitungsreporter davon überzeugen könnt, dass es sich bei eurem Material um eine wichtige Story handelt, und er über euch berichtet, kann sich sogar noch stärker auf den PageRank auswirken als ein Link vom Open Directory Project.
In der Vergangenheit hatten Leute sogar Listen mit den von ihnen begehrten Links. Und es ist nicht so, dass das Open Directory Project im Vergleich etwas Besonderes wäre. Es ist zwar ein sehr bekanntes Verzeichnis, ein Eintrag stellt jedoch keine Voraussetzung dar. Es ist nicht notwendig, einen Link von DMOZ vorweisen zu können. Wenn also eure Konkurrenz einen Link vom Open Directory Project hat, ihr aber nicht, müsst ihr euch deswegen keine großen Gedanken machen. Ich würde mich davon nicht aus der Ruhe bringen lassen. Ich würde mir überlegen, was ich unternehmen kann, um meine Website so interessant zu gestalten, dass Leute Links auf die Website setzen wollen. Und diese Links können auch von anderen Quellen als DMOZ stammen.
Ich hoffe, die Informationen und der kleine Einblick in die Hintergründe zu unserer aktuellen Haltung zu DMOZ und dem Open Directory Project helfen euch weiter.
Veröffentlicht von Daniela Loesser, Search Quality Team
Mühelos Zeit sparen mit "Status der Website"
Montag, 10. Oktober 2011
Wir hören immer wieder von Webmastern, dass sie bei ihrer Zeiteinteilung Prioritäten setzen müssen. Einige verwalten dutzende oder sogar hunderte Websites für Kunden. Andere hingegen leiten ihr eigenes Unternehmen und haben zwischen Finanzfragen und Inventarangelegenheiten nur eine knappe Stunde für die Pflege der Website übrig. Um euch dabei zu helfen, euch auf die wichtigen Probleme zu fokussieren, führt Webmaster-Tools das Konzept "Status der Website" ein. Wir haben die Startseite von Webmaster-Tools umstrukturiert, um Websites hervorzuheben, die Statusprobleme haben. Damit könnt ihr auf einen Blick sehen, worauf ihr euch zunächst konzentrieren müsst, ohne dass ihr erst alle Berichte zu jeder einzelnen Website in Webmaster-Tools durchgehen müsst.
So sieht die neue Startseite aus:
Wie ihr seht, werden Websites mit Statusproblemen
in der Liste ganz oben angezeigt. (Ihr könnt jederzeit zur alphabetischen Liste der Websites zurückkehren, wenn ihr diese Reihenfolge bevorzugt.) Um die spezifischen Probleme einer Website anzuzeigen, klickt auf das Symbol für den Status der Website oder auf den Link "Status der Website überprüfen" neben der entsprechenden Website:
Diese Homepage ist derzeit nur verfügbar, wenn ihr 100 oder weniger Websites in eurem Webmaster-Tools Asccount habt (unabhängig davon, ob die Seiten bestätigt sind oder nicht). Wir arbeiten daran, diese Änderung für alle Seiten verfügbar zu machen. Wenn ihr mehr als 100 Websites habt, könnt ihr den Status dieser oben im Dashboard der einzelnen Seiten sehen.
Im Moment erfasst die Statusprüfung für eure Website drei Probleme:
1. Wurde Malware auf der Website gefunden?
2. Wurden wichtige Seiten mit unserem
Tool zum Entfernen von URLs
entfernt?
3. Ist das Crawlen wichtiger Seiten über "robots.txt" blockiert?
Ihr könnt auf die Einträge klicken, um unsere Ergebnisse zu eurer Website im Detail einzusehen. Wenn das Symbol für den Status der Website und der Link "Status der Website überprüfen" nicht neben dem Namen der Website erscheint, haben wir auf dieser Website keine solchen Probleme festgestellt (Gratulation!).
Ein Wort noch zu "wichtigen Seiten": Wie ihr wisst, könnt ihr eine vollständige Liste aller entfernten URLs über "Website-Konfiguration" > "Crawler-Zugriff" > "URL entfernen" erhalten. Außerdem seht ihr über "Diagnose" > "Crawling-Fehler" > "Durch robots.txt gesperrt" alle URLs, die wir wegen "robots.txt" nicht crawlen konnten. Da Webmaster Inhalte häufig absichtlich blockieren oder entfernen, sollen mögliche Statusprobleme nur angezeigt werden, wenn wir glauben, ihr habt eine Seite versehentlich blockiert oder entfernt. Deshalb konzentrieren wir uns auf die "wichtigen Seiten". Im Moment beurteilen wir die Wichtigkeit einer Seite danach, wie viele Klicks auf sie entfallen (zu finden unter "Ihre Website im Web" > "Suchanfragen"). Im Rahmen der Weiterentwicklung unserer Statusprüfungen fügen wir möglicherweise weitere Faktoren hinzu.
Diese drei Probleme, nämlich Malware, entfernte URLs und blockierte URLs, sind nicht die einzigen Faktoren, die den Status einer Website negativ beeinflussen können. Wir hoffen, unsere Prüfungen zur Feststellung des Status einer Website in Zukunft weiter ausbauen zu können. Natürlich ist nichts so wertvoll, wie euer eigenes Urteilsvermögen und Wissen, was auf eurer Website passiert. Wir hoffen jedoch, dass ihr mit diesen Veränderungen schneller wichtige Probleme auf euren Websites erkennt, ohne alle Daten und Berichte durchforsten zu müssen.
Nachdem ihr alle aufgezeigten Statusprobleme für eine Website ausgeräumt habt, dauert es normalerweise mehrere Tage, bis der Warnhinweis nicht mehr im Webmaster-Tools-Konto angezeigt wird. Das liegt daran, dass wir die Seite erneut crawlen müssen, eure Veränderungen registrieren und dann diese Informationen erst in Google Websuche und Webmaster-Tools verarbeiten müssen. Wenn nach rund einer Woche weiterhin ein Warnhinweis zum Status der Website angezeigt wird, ist das Problem unter Umständen nicht gelöst. Ihr könnt gerne in unserem
Webmaster-Hilfeforum
um Hilfe zum Auffinden des Problems bitten... und uns eure Meinung mitteilen!
Gepostet von
Susan Moskwa
, Webmaster Trends Analyst (Veröffentlicht von
Dominik Zins
, Search Quality)
An alle Top-Beitragenden: Ihr seid die Besten!
Freitag, 7. Oktober 2011
Das TC Summit war ein Fest! Wie
an dieser Stelle vor einiger Zeit angekündigt
, haben wir kürzlich 250 Top-Beitragende aus der ganzen Welt nach Kalifornien eingeladen. Wir wollten ihnen die Möglichkeit geben, sich mit den Mitarbeitern aus den Foren, den Software-Ingenieuren und Produktmanagern auszutauschen. Außerdem wollten wir uns natürlich für ihre großartige Unterstützung in den Foren bedanken!
Unsere Kollegen Adrianne und Brenna haben auf dem offiziellen Google Blog schon einen
Bericht zum Summit
veröffentlicht. Für uns Suchmaschinisten bleibt da nicht viel hinzuzufügen. Wir haben es genossen die Top-Beitragenden mal in natura zu treffen - viele von ihnen zum ersten Mal. Wir haben das Gefühl, dass ihr auch eine gute Zeit hattet. Lasst uns ein paar Top-Beitragende zitieren, die jeden Tag den Unterschied für die Community ausmachen:
Sasch Mayer auf
Google+
(Webmaster TC, im Englischen)
“Aus einer ganzen Reihe von Gründen ist dieses Event etwas besonderes für mich und wird es auch immer bleiben. Nicht, weil ich eine der relativ wenigen Personen war, die zu diesem Spaß im `Plex eingeladen wurden, sondern weil dieses Treffen es möglich gemacht hat, dass sich die Top-Beitragenden aus aller Welt mal endlich persönlich kennenlernen konnten.”
Herbert Sulzer, a.k.a. Luzie auf
Google+
(Webmaster TC im Englischen, Deutschen und Spanischen)
“Hehehe! Fun, fun fun, this was all fun :D Huhhh”
Aygul Zagidullina auf
Google+
(Web Search TC im Englischen)
“Es war eine fantastische, beeindruckende und unvergessliche Erfahrung, so viele andere Top-Beitragende aus den verschiedensten Produktforen zu treffen und die Chance zu haben, mit so vielen Googlern zu sprechen, die an den unterschiedlichsten Produkten arbeiten!”
Natürlich haben wir auch jede Menge konstruktives Feedbacks erhalten.Transparenz und Kommunikation standen ganz oben auf der Agenda. Wir arbeiten gerade daran, unsere Aktivitäten im Bereich der Kommunikation zu erweitern, zum Beispiel innerhalb der
Webmaster-Tools
. Ihr dürft gespannt sein! Wenn ihr es übrigens noch nicht getan habt, denkt bitte daran, die
Weiterleitungsoption im Nachrichten-Center der Webmaster-Tools
einzuschalten, damit ihr alle Nachrichten direkt an eure Email-Adresse geschickt bekommt. In der Zwischenzeit habt bitte ein Auge auf unsere Webmasterzentrale und beteiligt euch weiterhin an den Diskussionen im
Webmasterforum
.
Stellvertretend für alle Google Guides, die am TC Summit teilgenommen haben, möchten wir uns an dieser Stelle bei euch bedanken. Ihr seid einfach super! :-)
Google Guides und Top-Beitragende kamen aus aller Welt in Kalifornien zusammen.
Hier seht ihr Top-Beitragende und Google Guides aus den Webmaster- und Search-Foren nach einer der Sessions.
Nach einem Tag voller Präsentationen und Workshops...
...haben wir dann gemacht, wozu wir ursprünglich gekommen waren...
...gefeiert und eine gute Zeit zusammen verbracht!
Gepostet von
Esperanza Navas
,
Yves Taquet
,
Uli Lutz
&
Kaspar Szymanski
, Google Search Quality (Übersetzt von
Dominik Zins
, Search Quality)
Neuorganisation interner und externer Rückverweise
Mittwoch, 5. Oktober 2011
Heute nehmen wir eine Änderung an der Kategorisierung von Linknamen in den
Webmaster-Tools
vor. Wie ihr wisst, werden Links, die auf eure Website verweisen, in den Webmaster-Tools in zwei verschiedenen Kategorien aufgeführt, und zwar
Links von anderen Websites
und Links
innerhalb eurer Website
. Durch das heutige Update ändert sich nichts an der Gesamtanzahl eurer Links. Vielmehr soll es dafür sorgen, dass die Darstellung von Rückverweisen eher eurer Vorstellung davon entspricht, welche Links tatsächlich von eurer Website bzw. von anderen Websites stammen.
In den Webmaster-Tools könnt ihr viele verschiedene Typen von Websites verwalten, etwa einen einfachen Domain-Namen (beispiel.de), eine Sub-Domain (www.beispiel.de oder katzen.beispiel.de) oder eine Domain mit einem Pfad zu einem Unterordner (www.beispiel.de/katzen/ oder www.beispiel.de/nutzer/katzenfan/). Bisher wurden nur Links, die mit der genauen URL eurer Website beginnen, als interne Links kategorisiert, das heißt, wenn ihr www.beispiel.de/nutzer/katzenfan/ als eure Website angegeben habt, wurde www.beispiel.de/nutzer/katzenfan/profil.html als interner Link kategorisiert, Links von www.beispiel.de/nutzer/ oder www.beispiel.de jedoch als externe Links. Falls ihr www.beispiel.de als eure Website angegeben habt, bedeutete dies außerdem, dass Links von beispiel.de als extern eingestuft wurden, weil sie nicht mit der gleichen URL wie eure Website beginnen bzw. nicht "www" enthalten.
beispiel.de und www.beispiel.de werden mittlerweile von den meisten Nutzern als dieselbe Website interpretiert, deshalb ändern wir das jetzt. Das heißt, wenn ihr entweder beispiel.de oder www.beispiel.de als Website hinzufügt, werden sowohl Links von der Version der Domain mit "www" als auch solche von der Version ohne "www" als interne Links kategorisiert. Wir haben dies auch für Sub-Domains umgesetzt, da viele Inhaber von Domains auch Eigentümer der entsprechenden Sub-Domains sind. katzen.beispiel.de oder haustiere.beispiel.de werden also ebenfalls als interne Links für www.beispiel.de eingestuft.
Zum Vergrößern der Darstellung bitte einfach auf diese klicken
Wenn ihr Inhaber einer Website seid, die sich unter einer Sub-Domain befindet, etwa
googlewebmastercentral-de.blogspot.com
, oder in einem Unterordner, z. B.
www.google.com/support/webmasters/
, und Ihr nicht im Besitz der Stamm-Domain seid, werden unter euren internen Links weiterhin nur Links von URLs mit der betreffenden Sub-Domain oder dem betreffenden Unterordner angezeigt. Alle anderen Links werden als extern kategorisiert. Wir haben einige Änderungen am Backend vorgenommen, sodass diese Zahlen noch genauer ausfallen sollten.
Solltet Ihr Inhaber einer Stamm-Domain wie beispiel.de oder www.beispiel.de sein, kann es sein, dass die Anzahl eurer externen Links durch diese Änderung offenbar zurückgeht. Dies liegt daran, dass einige URLs, die früher als externe Links eingestuft wurden, jetzt wie oben beschrieben im Bericht über interne Links auftauchen. Die Gesamtanzahl eurer Links, also aller internen und externen Links, sollte von dieser Änderung nicht beeinflusst werden.
Falls ihr Fragen habt, könnt ihr wie immer Kommentare abgeben oder unser
Webmaster-Hilfeforum
besuchen.
Gepostet von Susan Moskwa, Webmaster Trends Analyst (Veröffentlicht von Dominik Zins, Search Quality)
Wieso hat sich mein PageRank verschlechtert?
Montag, 3. Oktober 2011
Heute gibt Matt Cutts wieder einige Antworten zum Thema PageRank in der Google-Toolbar und erklärt, warum der PageRank einer Seite sich verschlechtern kann.
Die heutige Frage kommt aus Turin, Italien. Sie lautet: "Ich verwende die Google-Toolbar zur Überprüfung von PageRank. Ich habe im Internet gelesen, dass sie veraltete und ziemlich unzuverlässige Daten liefert. Kann ich in Echtzeit verlässliche PageRank-Informationen über meine verwalteten Websites erhalten? Und wie erkenne ich die Ursachen für einen verschlechterten PageRank?"
Die Informationen aus der Google-Toolbar werden drei- bis viermal im Jahr aktualisiert. Sie werden nicht jeden Tag aktualisiert, weil wir nicht möchten, dass Webmaster sich zu sehr auf die grüne Anzeige in der Google-Toolbar konzentrieren und wichtige Aspekte wie Titel, Crawlbarkeit und gute Inhalte vernachlässigen. Wenn nur der PageRank angezeigt und täglich aktualisiert wird, konzentrieren sich einige Leute nur darauf. Wir wollten diese Fixierung auf Backlinks vermeiden und verhindern, dass Leute sich nur auf PageRank und die Toolbar konzentrieren.
Zurück zur Frage, ob die Daten unzuverlässig sind. Sie sind nicht unzuverlässig, sondern auf einer Skala von 0 bis 10 gerundet. Man kann hier also nicht unbedingt von "unzuverlässig" sprechen. Zur Frage, wie man die Ursachen für einen verschlechterten PageRank erkennt: Wenn euer PageRank beispielsweise nur durch einen richtig guten Link zustande kam und ihr nun nicht mehr auf dieser Website verlinkt seid, hat sich euer PageRank möglicherweise dadurch verschlechtert. Wenn ihr eure internen Verlinkungen durcheinandergebracht habt und etwas mit euren Canonical-Tags nicht stimmt, also wenn z. B. www und nicht-www zu vollkommen unterschiedlichen Websites führen, eben bei solchen Problemen mit den "canonical"-Beziehungen, dann kann sich euer PageRank auch dadurch verschlechtert haben.
Aber eine der häufigsten Ursachen für einen schlechteren PageRank, zumindest bei der Google-Toolbar, ist der Verkauf von Links. Wenn sich euer PageRank plötzlich um 30% verschlechtert hat und ihr Links verkauft habt, die PageRank weitergegeben haben, ist der Grund dafür, dass der Verkauf von solchen Links gegen unsere Qualitätsrichtlinien verstößt. Und wenn man mal darüber nachdenkt, kann man das gut nachvollziehen. Es kommt einer Bestechung gleich: Man gibt jemandem Geld und bekommt dafür eine Empfehlung. Das wird in der Suchmaschine aber nicht entsprechend deutlich gemacht. Wenn das also bei einer Website der Fall ist, kann das der Grund für einen schlechteren PageRank in der Toolbar sein.
Trifft das auf euch zu, müsst ihr nur die Links, die ihr verkauft habt, entfernen und einen Antrag auf erneute Überprüfung stellen und sagen: "Hey, ich habe Links verkauft. Sie haben PageRank weitergegeben. Mein PageRank hat sich verschlechtert, deshalb habe ich die Links entfernt. Ihr könnt das überprüfen. Und dann gebt mir bei Google bitte noch eine Chance." Wenn wir das überprüft haben und sehen, dass der gute Wille da ist, und wir ziemlich überzeugt sind, dass ein Verkauf von PageRank nicht wieder vorkommt, dann wird euer PageRank oftmals wiederhergestellt. Ich hoffe, das war euch für diese häufigen Fragen zu PageRank eine Hilfe.
Veröffentlicht von Daniela Loesser, Search Quality Team
Labels
#NoHacked
2
2017
1
Accessibility
13
AJAX
1
AMP
7
Android
2
api
1
App-Indexierung
3
Best Practices
99
Bildersuche
2
captcha
1
Chrome
4
Code
12
Crawling
1
Crawling und Indexierung
126
Diskussionsforum
15
Duplicate Content
17
Dynamic Rendering
1
Einsteiger
8
Event
1
events
1
Feedback
1
Geo-Targeting
11
Google Analytics
6
Google Dance
1
Google News
1
Google Places
4
Google-Assistant
1
Google-Suche
59
Google+
9
Hacking
16
Hangouts
1
https
3
JavaScript
3
Kanonische URL
1
Kommentare
1
Konferenz
19
Lighthouse
3
Links
18
Malware
17
Mobile
38
Mobile-first indexing
1
Nachrichten-Center
16
Optimisation
3
PageSpeed Insights
2
Penalties
1
Performance
3
Ranking
1
reCaptcha v3
1
Rendering
2
Rich Snippets
18
Richtlinien für Webmaster
36
robots.txt
7
Safe Browsing
5
Search Console
19
Search Results
1
Security
4
Seitenzugriff
1
SEO
4
Sicherheit
38
Site Clinic
5
Sitemaps
30
Spam Report
9
SSL
1
Structured Data
8
Tools und Gadgets
17
Verschlüsselung
1
Video
132
Webmaster blog
1
Webmaster Community
1
Webmaster-Academy
1
Webmaster-Tools
154
webspam
3
Archiv
2020
Nov.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
2019
Dez.
Nov.
Okt.
Sept.
Juni
Mai
Feb.
Jan.
2018
Dez.
Nov.
Okt.
Sept.
Juli
Juni
Mai
Apr.
Feb.
Jan.
2017
Dez.
Nov.
Juni
Apr.
März
Jan.
2016
Nov.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Jan.
2015
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Mai
Apr.
März
Feb.
Jan.
2014
Nov.
Okt.
Sept.
Aug.
Juni
Mai
Apr.
März
Feb.
Jan.
2013
Dez.
Nov.
Okt.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
Jan.
2012
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
Jan.
2011
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
Jan.
2010
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
Jan.
2009
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
Jan.
2008
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feb.
Jan.
2007
Dez.
Nov.
Okt.
Sept.
Aug.
Juli
Juni
Mai
Apr.
März
Feed
Forum für Webmaster
Webmaster-Sprechstunden
Webmaster-Tools-Hilfe
Developers-Site für Webmaster