Wir sind stolz auf unsere deutschsprachigen Nutzer, die uns im Interesse der gesamten Internet-Community über möglichen Mißbrauch durch einige wenige opportunistische Webmaster informieren. Wir schätzen das um so mehr, als PageRank (und somit Google Search) auf einem demokratischen Prinzip basiert, das vom Webmaster ausgeht, der durch Verlinkung ein positives Votum für andere Webseiten abgibt.
Im Jahr 2007 wollen wir als Erweiterung und Ergänzung dieses demokratischen Konzepts das Wissen unserer User über Google-konforme Webmasterpraktiken weiter erhöhen (u.a. mithilfe dieses deutschsprachigen Webmasterblogs). Nicht zuletzt durch die aktive Einflußnahme von Userseite läßt sich ein Prozeß anstoßen, an dessen Ausgangspunkt der informierte User steht, der Formen von Webspam überhaupt identifizieren kann und sich zudem via Spam Report dagegen einsetzt. Denn zum einem profitieren alle Nutzer von einer maximalen Suchqualität. Zum anderen werden die "Spammaster" unter den Webmastern merken, daß sich Ranking-Manipulationsversuche nicht lohnen.
Unser Spam Report Formular liegt in zwei unterschiedlichen Varianten vor: Der authentifizierte Spam Report, der eine Registrierung über die Webmaster-Tools voraussetzt, sowie der nicht-authentifizierte Spam Report. Derzeit gehen wir jedem Spam Report von registrierten Usern nach. Bei Spam Reports, die ohne Authentifizierung gesendet werden, wird zunächst deren Priorität bestimmt und bei hoher Priorität werden diese ebenfalls analysiert.
Wenn sich also einmal die Vermutung aufdrängt, daß das Ranking eines Suchergebnisses nicht durch Contentarbeit oder legitime SEO verdient wurde, dann ist das die perfekte Gelegenheit für einen Spam Report. Denn jeder einzelne Spam Report unterstützt uns beim kontinuierlichen Optimieren unserer Suchalgorithmen.
An weiteren Informationen interessiert? Im folgenden gibt es Antworten auf die drei häufigsten User-Fragen.
FAQs zum Thema Spam Reports:
F: Was passiert mit einem authentifizierten Spam Report bei Google?A. Authentifizierte Spam Reports werden analysiert und dann für die Evaluierung neuer Spamerkennungsalgorithmen sowie zur Identifizierung von Webspam-Trends verwendet. Ziel dabei ist es, zukünftig alle Seiten mit vergleichbaren Manipulationsversuchen automatisch zu detektieren und sicherzustellen, daß unsere Algorithmen diese Seiten entsprechend im Ranking listen. Wir wollen uns also nicht auf ein ineffizientes Katz-und-Maus-Spiel mit dem einzelnen Webmaster einlassen, der zu tief in die SEO-Trickkiste gegriffen hat.
F: Warum sind in manchen Fällen keine unmittelbaren Konsequenzen eines Spam Reports erkennbar?A: Wir bei Google sind stets bemüht, auf Engineering-Ebene unsere Spamerkennungsalgorithmen zu optimieren. Gleichzeitig gehen wir jedoch auch einzelnen Webseiten nach, auf die wir per Spam Report hingewiesen werden. Manchmal sind unsere Maßnahmen jedoch nicht unmittelbar für Außenstehende erkennbar. Daher ist es auch für das Evaluiert-Werden einer URL nicht nötig, mehrere Spam Reports für ein und dieselbe URL an uns zu schicken. Es gibt viele Gründe, warum die Reaktion von Google auf einen Spam Report für User nicht direkt nachvollziehbar ist. Die folgenden Gründe sind nur einige davon:
F: Kann ein User mit Feedback für einen Spam Report rechnen?A: Wir wissen um diesen Wunsch, z.B. als Bestätigung oder einfach als Zeichen, daß der Spam Report nicht im System untergegangen ist. Gerne täten wir das. Doch wir glauben, daß wir mehr erreichen, wenn wir auf der Datengrundlage der eingegangenen Spam Reports an der Robustheit unserer Algorithmen feilen. Allerdings denken wir darüber nach, wie wir zukünftig all unseren Nutzern Feedback kommunizieren können.
Um diese Daten für Euch noch nützlicher zu machen, unterscheiden wir zwischen externen und internen Links. Doch welche Links gehören in welche Kategorie?
Was sind externe Links?
Externe Links sind Links von Webseiten, die nicht zu Eurer Webdomain gehören. Wenn Ihr Euch zum Beispiel die Links für http://www.google.com/ anschaut, werden all die Links, die nicht von Seiten irgendeiner Subdomain von http://www.google.com/ (wie z.B. http://video.google.com/) kommen, als externe Links gelistet.
Was sind interne Links?
Interne Links dagegen sind diejenigen Links auf Seiten, die zu Eurer eigenen Domain gehören. Wenn Ihr Euch zum Beispiel die Links für http://www.google.com/ anschaut, werden all diejenigen Links, die von Seiten irgendeiner Subdomain von http://www.google.com/ kommen, als interne Links gelistet.
Wie Ihr Euch Links zu Seiten Eures Webauftritts anschauen könnt
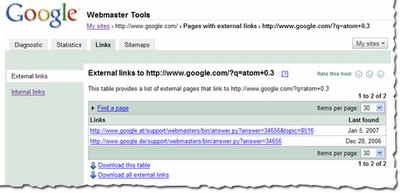
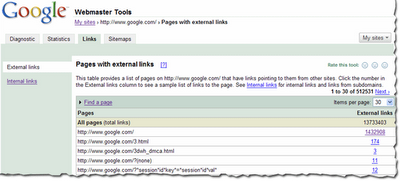
Ihr könnt Euch die Links zu Eurer Webseite ansehen, indem Ihr einen verifizierten Webauftritt in Eurem Webmaster-Tools-Account auswählt und auf den neuen Reiter "Links" klickt. Nun seht Ihr auf der linken Seite zwei Optionen: "Externe Links" und "Interne Links", wobei die Option "Externe Links" dabei bereits vorausgewählt ist. Eine Tabelle mit den Seiten Eures Webauftritts wird aufgeführt (s.u.). In der ersten Spalte sind Eure Seiten gelistet, in der zweiten Spalte jeweils die Anzahl der externen Links, die auf die jeweilige Seite zeigen. (Möglicherweise werden hierbei nicht 100% der externen Links auf die jeweilige Seite angezeigt.)
Außerdem könnt Ihr der Tabelle auch die Gesamtzahl der externen Links entnehmen, die wir Euch anzeigen können.
Wenn Ihr nun in dieser Übersicht die verlinkten Zahlen anklickt, gelangt Ihr zu einer detaillierten Auflistung der Links für die jeweilige Seite. In dieser Detailansicht seht Ihr eine Liste aller externen Seiten, die auf die ausgewählte Seite Eures eigenen Webauftritts verlinken, sowie den Zeitpunkt, zu dem wir diese Links das letzte Mal gecrawlt haben. Da die Option "Externe Links" ausgewählt ist, werden hier natürlich nur die externen Links zu Euren Seiten angezeigt.
Wie Ihr Links zu einer bestimmten Seite Eures Webauftritts finden könnt
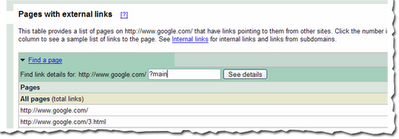
Um die Links zu einer bestimmten Seite Eures Webauftritts zu finden, müsst Ihr zunächst einmal diese Seite in der Übersichtsansicht mit der Liste aller Seiten finden. Dazu könnt Ihr durch die Tabelle navigieren oder - viel schneller - den praktischen "Eine Seite suchen"-Link oben in der Tabelle nutzen. Gebt in das Feld einfach die URL ein und klickt dann "Siehe Details". Es reicht meist aus, nur einen Teil der URL anzugeben. Sucht Ihr zum Beispiel die Seite mit der URL http://www.google.com/?main, könnt Ihr "?main" in das Formularfeld eintippen. Das bringt Euch direkt zur Detailansicht mit den Links für die Seite http://www.google.com/?main.
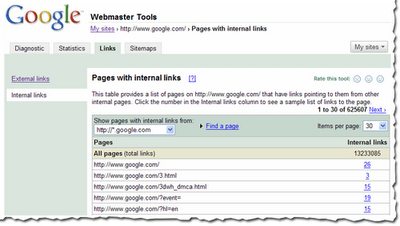
Um interne Links zu Seiten Eures Webauftritts anzusehen, klickt Ihr auf "Interne Links" in der Auswahl auf der linken Seite. So gelangt Ihr zu der Übersichtstabelle, die (wie die Tabelle für die externen Links) Informationen über Eure Seiten auflistet, auf die interne Links zeigen.
In dieser Ansicht für interne Links könnt Ihr die Daten auch noch weiter filtern. Ihr könnt Euch etwa die Links von allen Subdomains Eurer Domain oder lediglich die Links von einer bestimmten Subdomain anzeigen lassen. Wenn Ihr zum Beispiel gerade die internen Links zu http://www.google.com/ betrachtet, könnt Ihr Euch entweder die Links aller Subdomains (z.B. http://video.google.com/) auflisten lassen oder nur Links von Seiten auf http://www.google.com/.
Wie Ihr Euch Linkdaten herunterladen könnt
Es gibt drei verschiedene Möglichkeiten, Linkdaten für Eure Seite herunterzuladen: Erstens könnt Ihr die Tabelle, von der aus Ihr zu allen Übersichts- und Detailansichten gelangt, herunterladen. Am nützlichsten ist vermutlich die zweite Möglichkeit, nämlich die Liste der externen Links zu Euren Seiten. Hierbei könnt Ihr Euch die Liste aller zu Eurer Seite zeigenden Links zusammen mit Informationen über die Seite, auf die sie verweisen, sowie über den letzten Crawling-Zeitpunkt herunterladen. Drittens bieten wir einen ähnlichen Service zum Herunterladen der internen Links Eurer Seiten an.
Wir begrenzen das Datenvolumen, das Ihr für die beiden Linktypen herunterladen könnt (z.B. könnt Ihr derzeit bis zu einer Millionen externe Links herunterladen). Google kennt mehr Links, als anzeigt werden, aber die angezeigte Stichprobe ist dennoch wesentlich umfangreicher als die Anzahl von Links, die der link:-Operator gegenwärtig anbietet.
Besucht uns doch einfach auf den Seiten der Webmaster-Zentrale und erfahrt mehr über die Links Eurer Seite!
Post von Peeyush (Übersetzung von Daniela, Search Quality)
Anfang Dezember letzten Jahres wurden auf der Search Engine Strategies Konferenz im kalten Chicago viele von uns Googlern auf Duplicate Content angesprochen. Da wir uns bewusst sind, dass dies ein facettenreiches und auch ein wenig verwirrendes Thema ist, wollen wir dazu beitragen, einige Unklarheiten zu beseitigen.
Was ist Duplicate Content?
Als Duplicate Content werden üblicherweise Contentbereiche bezeichnet, die anderem Content - domainintern oder domainübergreifend - entweder genau gleichen oder diesem deutlich ähnlich sind. Meistens ist dies unbeabsichtigt oder zumindest kein böser Wille: Foren, die sowohl reguläre als auch für Handys optimierte Seiten generieren, Artikel in Onlineshops, die unter mehreren URLs gelistet (und – schlimmer noch – verlinkt) werden, usw. In manchen Fällen wird versucht, Content domainübergreifend zu duplizieren, um Suchergebnisse zu manipulieren oder um mehr Traffic mittels populärer oder „long-tail“ Suchanfragen zu generieren.
Was ist kein Duplicate Content?
Obwohl wir ein praktisches Übersetzungs-Tool anbieten, sehen unsere Algorithmen es nicht als Duplicate Content an, wenn der gleiche Artikel sowohl auf Englisch als auch auf Spanisch zur Verfügung steht. Ebenso müsst ihr euch keine Sorgen machen, dass gelegentlich auftretende doppelte Snippets (Zitate etc.) als Duplicate Content angesehen werden.
Warum ist Duplicate Content ein Thema für Google?
Unsere User wollen gewöhnlich einen vielfältigen Querschnitt an einzigartigem Content für ihre Suchanfragen erhalten. Sie sind verständlicherweise verärgert, wenn sie im Wesentlichen den gleichen Content innerhalb der Suchergebnisse sehen. Außerdem stört es Webmaster, wenn wir eine komplexe URL (example.com/contentredir?value=shorty-george⟨=en) anstatt der von ihnen bevorzugten schönen URL zeigen (example.com/en/shorty-george.htm).
Was macht Google mit Duplicate Content?
Während des Crawlens und bei der Ausgabe von Suchergebnissen achten wir sehr darauf, Seiten mit verschiedener Information zu indexieren und anzuzeigen. Wenn es z. B. auf eurer Website sowohl eine reguläre Version als auch eine Druckansicht für Artikel gibt, von denen keine durch robots.txt oder mittels eines noindex-Metatags blockiert wird, dann suchen wir uns aus, welche Version wir listen. In seltenen Fällen steht hinter Duplicate Content die Absicht, unsere Rankings zu manipulieren und unsere User zu täuschen. Falls wir dies feststellen, nehmen wir entsprechende Anpassungen der Indizierung und des Rankings der beteiligten Websites vor. Wir konzentrieren uns jedoch lieber auf das Filtern als auf Anpassungen des Rankings … überwiegend ist also das „Schlimmste“, was Webmastern passieren kann, das Auftauchen der „weniger erwünschten“ Version einer Seite in unserem Index.
Wie können Webmaster Probleme mit Duplicate Content vermeiden?
Kurz gesagt, durch ein generelles Bewusstsein für den Umgang mit Duplicate Content und ein paar Minuten für durchdachte, präventive Pflege eurer Website helft ihr uns dabei, unseren Usern einzigartigen und relevanten Content zu bieten.
Original
V o r h a n g a u f - Willkommen zur Premiere des deutschsprachigen Blogs der Google Webmaster-Zentrale!
Der erste Grundsatz unserer Philosophie lautet „Der Nutzer steht an erster Stelle und alles Weitere ergibt sich von selbst.“. Diesem Prinzip fühlen wir uns bei Google verpflichtet. Und genau deswegen wollen wir mit der deutschen Version unseres Google Webmaster Central Blogs eine Plattform zur Kommunikation mit unseren Usern schaffen.
An dieser Stelle werden wir Euch Informationen aus erster Hand zu Fragen der Indizierung, zum Ranking, zu unseren Qualitätsrichtlinien für Webmaster und zur Gestaltung von Webseiten im Sinne der Nutzer bieten. Anfänglich werden wir in diesem Webmaster Blog ausgewählte Einträge des englischen Webmaster Central Blogs in deutscher Übersetzung veröffentlichen. Im Laufe der Zeit werden auch Einträge erscheinen, die besonders für Webmaster des deutschen Sprachraums von Interesse sind.
Zwar haben wir Matts Cutts nicht zwischenzeitlich die Sprache von Goethe beigebracht; auch Adam Lasnik haben wir nicht geklont. Stattdessen werden verschiedene Googler aus den Bereichen Web Search und Search Quality an dieser Stelle in regelmäßigen Zeitabständen bloggen.